
Page 100 - 中国全科医学2022-01
P. 100
http://www.chinagp.net E-mail:zgqkyx@chinagp.net.cn ·225·
本研究不同的特征筛选方法对模型性能存在影响。其中,
不筛选是为了纳入缺失值处理后的所有变量,了解模型
预测效果。然而,若只选择部分特征构建模型,可以大
大减少学习算法的运行时间,也可以增加模型的可解释
性。Boruta 筛选是选择出所有与因变量具有相关性的特
征集合,可以更全面的理解因变量的影响因素。Lasso
筛选相比于普通最小二乘估计,可在众多变量时快速有
效地提取出重要变量来简化模型。本研究假设检验单因
素分析中,Lasso 筛选在模型中表现较好,平均 AUC 为
(0.719±0.094),但在 5 个最佳模型里 Lasso 筛选并
未表现出较好的预测性能。集成学习、不填充、Boruta
筛选模型优于集成学习、不填充、Lasso 筛选模型。
本研究创新性之处:(1)国内尚未发现较成熟的
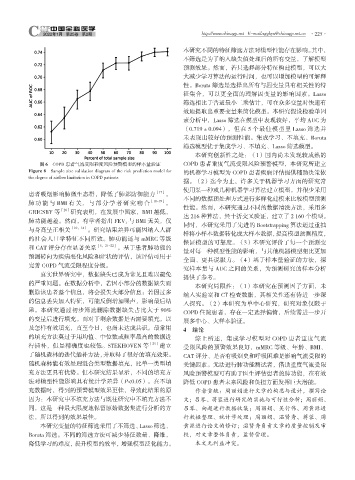
图 6 COPD 患者气流受限程度风险预警模型的样本量验证 COPD 患者重度气流受限风险预警模型,本研究所建立
Figure 6 Sample size validation diagram of the risk prediction model for 的机器学习模型为 COPD 患者疾病评估提供辅助决策依
the degree of airflow limitation in COPD patients
据。(2)迄今为止,许多关于机器学习方面的研究常
使用某一种或几种机器学习算法建立模型,并很少采用
[17]
患者吸烟影响肺微生态群,降低了肺部防御能力 。 不同的数据预处理方式进行多样化建模来比较模型预测
肺功能与 BMI 有关,与部分学者研究吻合 [18-19] 。 性能。然而,本研究通过不同的数据清洗方法,采用多
GRIGSBY 等 [20] 研究表明,在发展中国家,BMI 越低,
达 216 种算法,经十折交叉验证,建立了 2 160 个模型。
肺功能越差。然而,有学者指出 FEV 1 与 BMI 无关,仅 同时,本研究采用了先进的 Bootstrapping 算法通过重抽
与身高呈正相关 [10,14] 。研究结果差异可能因纳入人群
样将小样本数据转化成大样本数据,提高模型预测精度,
的社会人口学特征不同所致。肺功能还与 mMRC 等级 保证模型的可靠度。(3)本研究评价了每一个预测变
和 CAT 评分存在显著关系 [5,21-22] 。基于患者肺功能的
量对每一种模型性能的影响,与其他机器模型相比更加
预测转向为疾病恶化风险和症状的评估,该评估可用于
全面、更具说服力。(4)基于样本量验证的方法,探
完善 COPD 气流受限程度分级。
究样本量与 AUC 之间的关系,为预测研究的样本分析
真实世界研究中,数据缺失已成为常见且难以避免
提供了参考。
的严重问题。在数据分析中,若因小部分的数据缺失而
本研究局限性:(1)本研究在预测因子方面,未
删除该患者整个信息,将会损失大部分信息;若因过多
纳入实验室和 CT 检查数据,其相关性还有待进一步深
的信息丢失加入特征,可能反倒增加噪声,影响最后结 入探究。(2)本研究为单中心研究,研究对象仅限于
果。本研究通过初步筛选删除数据缺失占比大于 90% COPD 住院患者,存在一定选择偏倚,后续需进一步开
的变量后进行填充。而对于剩余数据是否需要填充,以 展多中心、大样本验证。
及怎样有效填充,直至今日,也尚未达成共识。最常用 4 结论
的填充方法莫过于用均值、中位数或频率最高的数据进 综上所述,集成学习模型对 COPD 患者重度气流
行插补,但是精确度也较低。STEKHOVEN 等 [23] 建立 受限风险的预警效果良好,mMRC 等级、年龄、BMI、
了随机森林的迭代插补方法,并取得了很好的填充效果。 CAT 评分、是否有吸烟史和呼吸困难是影响气流受限的
随机森林能有效处理混合类型数据填充,比单一类型填 关键因素。无法进行肺功能测试者,借助重度气流受限
充方法更具有优势。但本研究结果显示,不同的填充方 风险预警模型可有助于医生评估患者的肺功能,在有效
法对模型性能影响具有统计学差异(P<0.05)。在不填 降低 COPD 患者未来风险和负担方面发挥巨大潜能。
充数据时,得到的预警模型效果更佳,导致此结果的原 作者贡献:周丽娟进行文章的构思与设计,撰写论
因为:本研究中不填充方法与既往研究中不填充方法不 文;吕琴、蒋蓉进行研究的实施与可行性分析;周丽娟、
同,这是一种最大限度地保留原始数据集进行分析的方 吕琴、向超进行数据收集;周丽娟、吴行伟、周黄源进
法,所以得到的效果最佳。 行数据整理、统计学处理;周丽娟、温贤秀、蒋蓉、周
本研究变量的特征筛选采用了不筛选、Lasso 筛选、 黄源进行论文的修订;温贤秀负责文章的质量控制及审
Boruta 筛选。不同的筛选方法可减少特征数量、降维, 校,对文章整体负责,监督管理。
降低学习的难度,提升模型的效率,增强模型泛化能力。 本文无利益冲突。