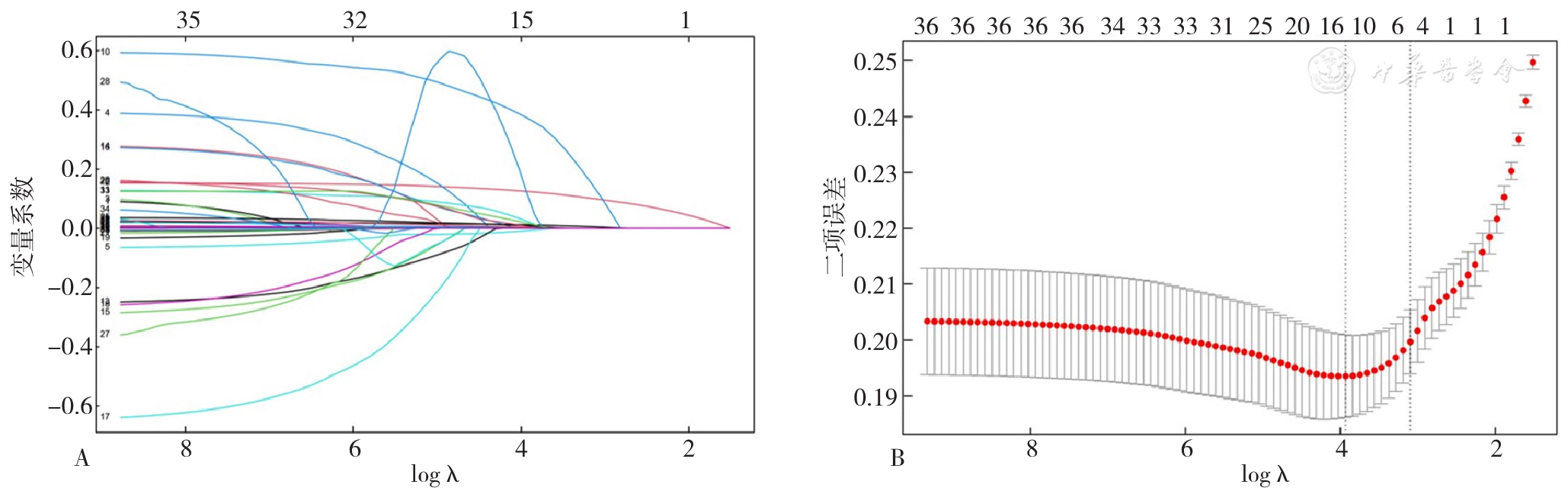
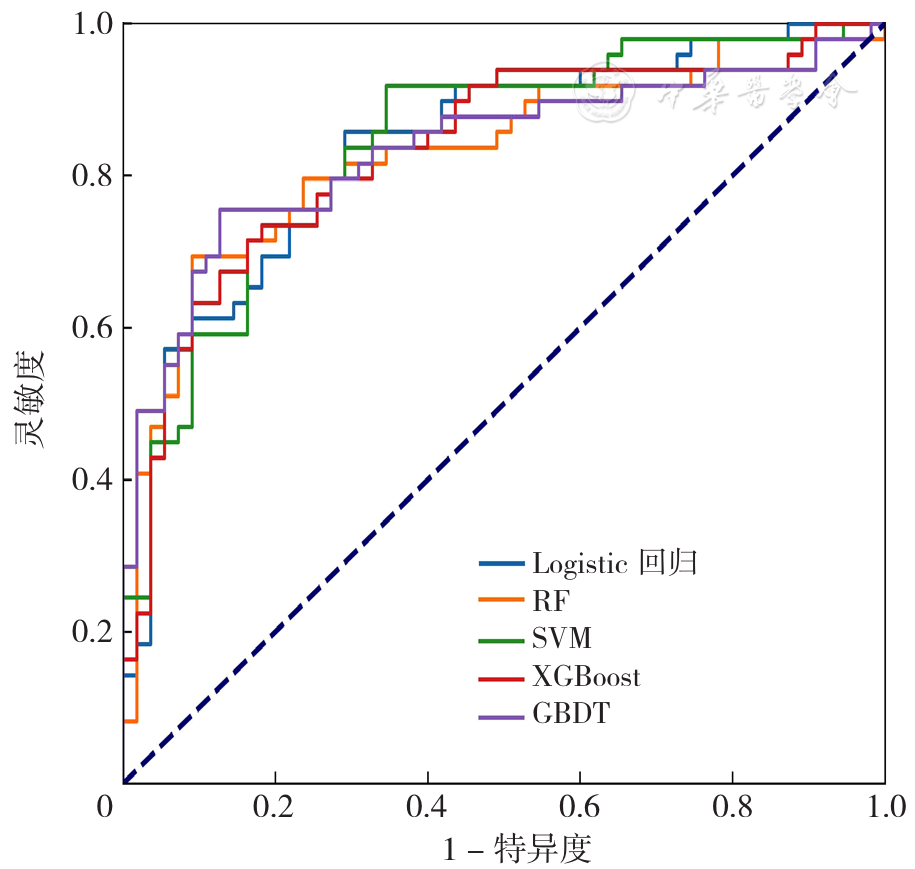
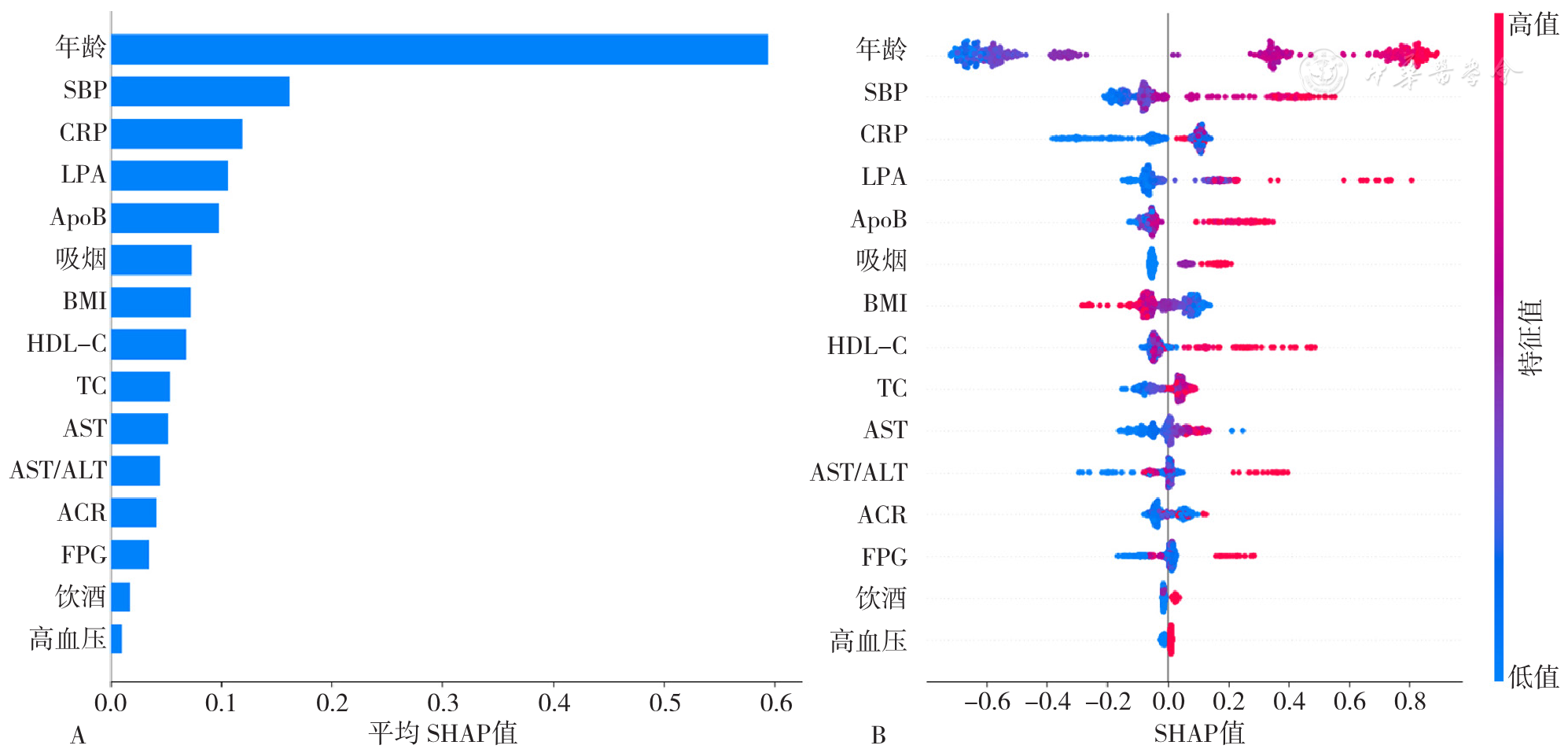
| [1] |
胡盛寿,王增武. 《中国心血管健康与疾病报告2022》概述[J]. 中国心血管病研究,2023,21(7):577-600.
|
| [2] |
SAKELLARIOS A I, BIZOPOULOS P, PAPAFAKLIS M I,et al. Natural history of carotid atherosclerosis in relation to the hemodynamic environment[J]. Angiology, 2017, 68(2):109-118. DOI: 10.1177/0003319716644138.
|
| [3] |
JOHRI A M, NAMBI V, NAQVI T Z,et al. Recommendations for the assessment of carotid arterial plaque by ultrasound for the characterization of atherosclerosis and evaluation of cardiovascular risk:from the American society of echocardiography[J]. J Am Soc Echocardiogr, 2020, 33(8):917-933. DOI: 10.1016/j.echo.2020.04.021.
|
| [4] |
|
| [5] |
PEN A, YAM Y, CHEN L,et al. Discordance between Framingham Risk Score and atherosclerotic plaque burden[J]. Eur Heart J, 2013, 34(14):1075-1082. DOI: 10.1093/eurheartj/ehs473.
|
| [6] |
|
| [7] |
RIDKER P M, BURING J E, RIFAI N,et al. Development and validation of improved algorithms for the assessment of global cardiovascular risk in women:the Reynolds Risk Score[J]. JAMA, 2007, 297(6):611-619. DOI: 10.1001/jama.297.6.611.
|
| [8] |
|
| [9] |
D'AGOSTINO R B Sr, VASAN R S, PENCINA M J,et al. General cardiovascular risk profile for use in primary care:the Framingham Heart Study[J]. Circulation, 2008, 117(6):743-753. DOI: 10.1161/CIRCULATIONAHA.107.699579.
|
| [10] |
WANG X J, LI W Z, SONG F J,et al. Carotid atherosclerosis detected by ultrasonography:a national cross-sectional study[J]. J Am Heart Assoc, 2018, 7(8):e008701. DOI: 10.1161/JAHA.118.008701.
|
| [11] |
|
| [12] |
TOUBOUL P J, HENNERICI M G, MEAIRS S,et al. Mannheim carotid intima-media thickness and plaque consensus (2004-2006-2011). An update on behalf of the advisory board of the 3rd,4th and 5th watching the risk symposia,at the 13th,15th and 20th European Stroke Conferences,Mannheim,Germany,2004,Brussels,Belgium,2006,and Hamburg,Germany,2011[J]. Cerebrovasc Dis, 2012, 34(4):290-296. DOI: 10.1159/000343145.
|
| [13] |
HORNE D J, CAMPO M, ORTIZ J R,et al. Association between smoking and latent tuberculosis in the U.S. population:an analysis of the National Health and Nutrition Examination Survey[J]. PLoS One, 2012, 7(11):e49050. DOI: 10.1371/journal.pone.0049050.
|
| [14] |
KUO C C, WEAVER V, FADROWSKI J J,et al. Arsenic exposure,hyperuricemia,and gout in US adults[J]. Environ Int, 2015, 76:32-40. DOI: 10.1016/j.envint.2014.11.015.
|
| [15] |
|
| [16] |
戴烨. 基于《中国高血压防治指南(2018修订版)》对某院门诊降压药应用情况的调查[J]. 中国社区医师,2022,38(12):11-13.
|
| [17] |
|
| [18] |
EXPERT PANEL ON DETECTION E. Executive summary of the third report of the national cholesterol education program(NCEP)expert panel on detection,evaluation,and treatment of high blood cholesterol in adults(adult treatment panelⅢ)[J]. JAMA, 2001, 285(19):2486-2497. DOI: 10.1001/jama.285.19.2486. |
| [19] |
诸骏仁,高润霖,赵水平,等. 中国成人血脂异常防治指南(2016年修订版)[J]. 中国循环杂志,2016,31(10):937-953.
|
| [20] |
|
| [21] |
WU D, CUI G S, HUANG X X,et al. An accurate and explainable ensemble learning method for carotid plaque prediction in an asymptomatic population[J]. Comput Methods Programs Biomed, 2022, 221:106842. DOI: 10.1016/j.cmpb.2022.106842.
|
| [22] |
YU J, ZHOU Y, YANG Q,et al. Machine learning models for screening carotid atherosclerosis in asymptomatic adults[J]. Sci Rep, 2021, 11(1):22236. DOI: 10.1038/s41598-021-01456-3.
|
| [23] |
龚军,钟小钢,谈军涛,等. "网格搜索+XGBoost"算法建立儿童脓毒性休克预测模型[J]. 解放军医学杂志,2020,45(12):1270-1276.
|
| [24] |
|
| [25] |
ZHANG Z D, JUNG C. GBDT-MO:gradient-boosted decision trees for multiple outputs[J]. IEEE Trans Neural Netw Learn Syst, 2021, 32(7):3156-3167. DOI: 10.1109/TNNLS.2020.3009776.
|
| [26] |
YE Z X, AN S Y, GAO Y X,et al. The prediction of in-hospital mortality in chronic kidney disease patients with coronary artery disease using machine learning models[J]. Eur J Med Res, 2023, 28(1):33. DOI: 10.1186/s40001-023-00995-x.
|
| [27] |
LIU R, WANG M Y, ZHENG T,et al. An artificial intelligence-based risk prediction model of myocardial infarction[J]. BMC Bioinformatics, 2022, 23(1):217. DOI: 10.1186/s12859-022-04761-4.
|
| [28] |
LIU F, YAO J, LIU C Y,et al. Construction and validation of machine learning models for sepsis prediction in patients with acute pancreatitis[J]. BMC Surg, 2023, 23(1):267. DOI: 10.1186/s12893-023-02151-y.
|
| [29] |
SU D, ZHANG X Y, HE K,et al. Individualized prediction of chronic kidney disease for the elderly in longevity areas in China:machine learning approaches[J]. Front Public Health, 2022, 10:998549. DOI: 10.3389/fpubh.2022.998549.
|
| [30] |
|
| [31] |
唐焱,周宏,罗光华,等. 缺血性脑卒中患者CAS斑块超声、CT血管造影及临床相关危险因素分析[J]. 中国动脉硬化杂志,2016,24(4):391-395.
|
| [32] |
|
| [33] |
|
| [34] |
XU S W, ILYAS I, LITTLE P J,et al. Endothelial dysfunction in atherosclerotic cardiovascular diseases and beyond:from mechanism to pharmacotherapies[J]. Pharmacol Rev, 2021, 73(3):924-967. DOI: 10.1124/pharmrev.120.000096.
|
| [35] |
|
| [36] |
|
| [37] |
DONG H L, CHEN W, WANG X Y,et al. Apolipoprotein A1,B levels,and their ratio and the risk of a first stroke:a meta-analysis and case-control study[J]. Metab Brain Dis, 2015, 30(6):1319-1330. DOI: 10.1007/s11011-015-9732-7.
|
| [38] |
|
| [39] |
|

 )
)